
Overview
Virtual thread가 아닌 일반 JVM thread의 쓰레딩 모델은 아래와 같다.
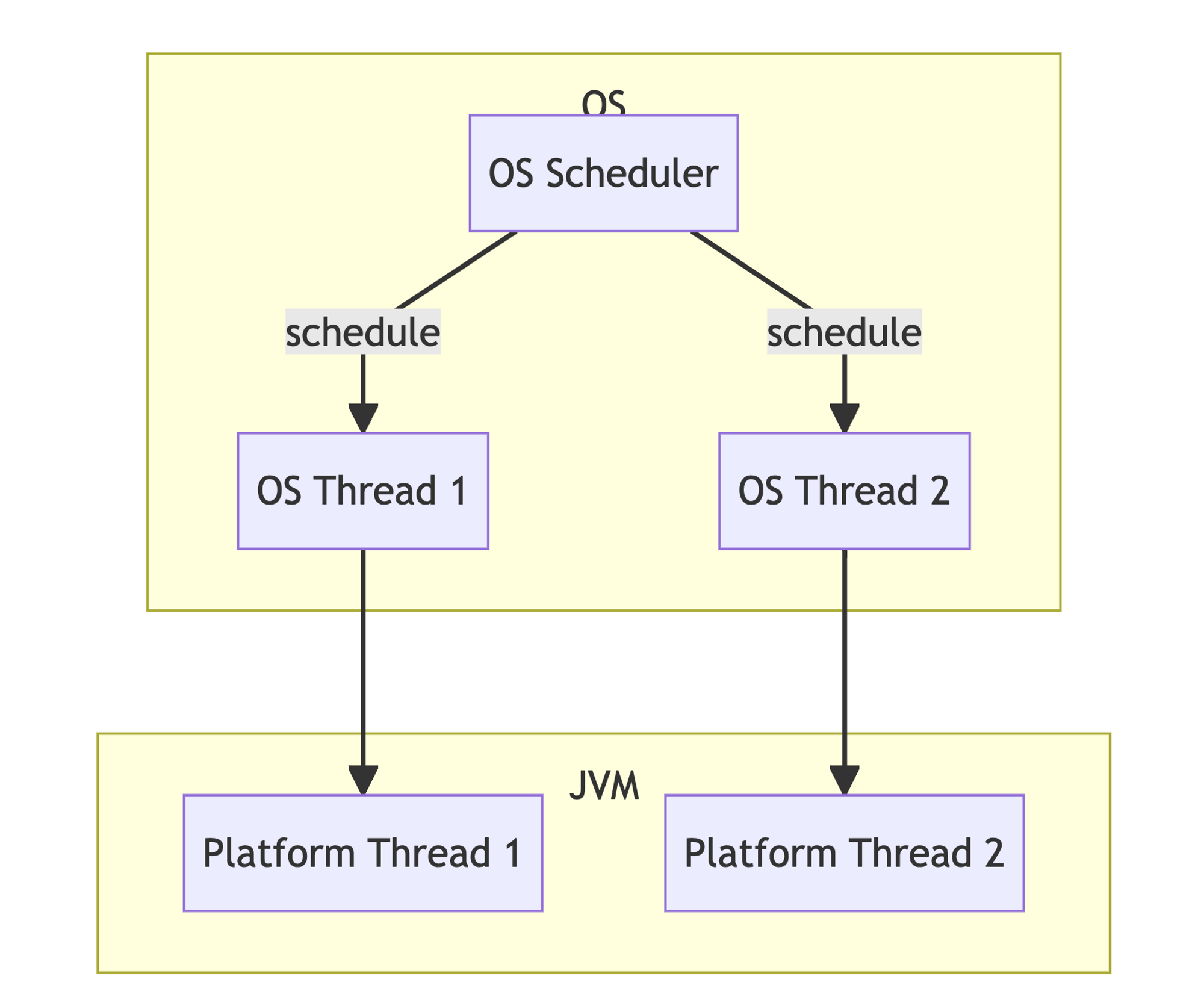
(출처: https://perfectacle.github.io/2022/12/29/look-over-java-virtual-threads/)JVM 쓰레드(platform thread)와 OS thread가 1대 1이다. 그래서 JVM 쓰레드의 컨텍스트 스위칭 = OS 쓰레드의 컨텍스트 스위칭이고, 컨텍스트 스위칭 시 OS 차원에서 스택을 완전히 재로딩해야 하므로 컨텍스트 스위칭의 비용이 크다.
반면 virtual thread는 아래와 같은 구조로 실행된다.
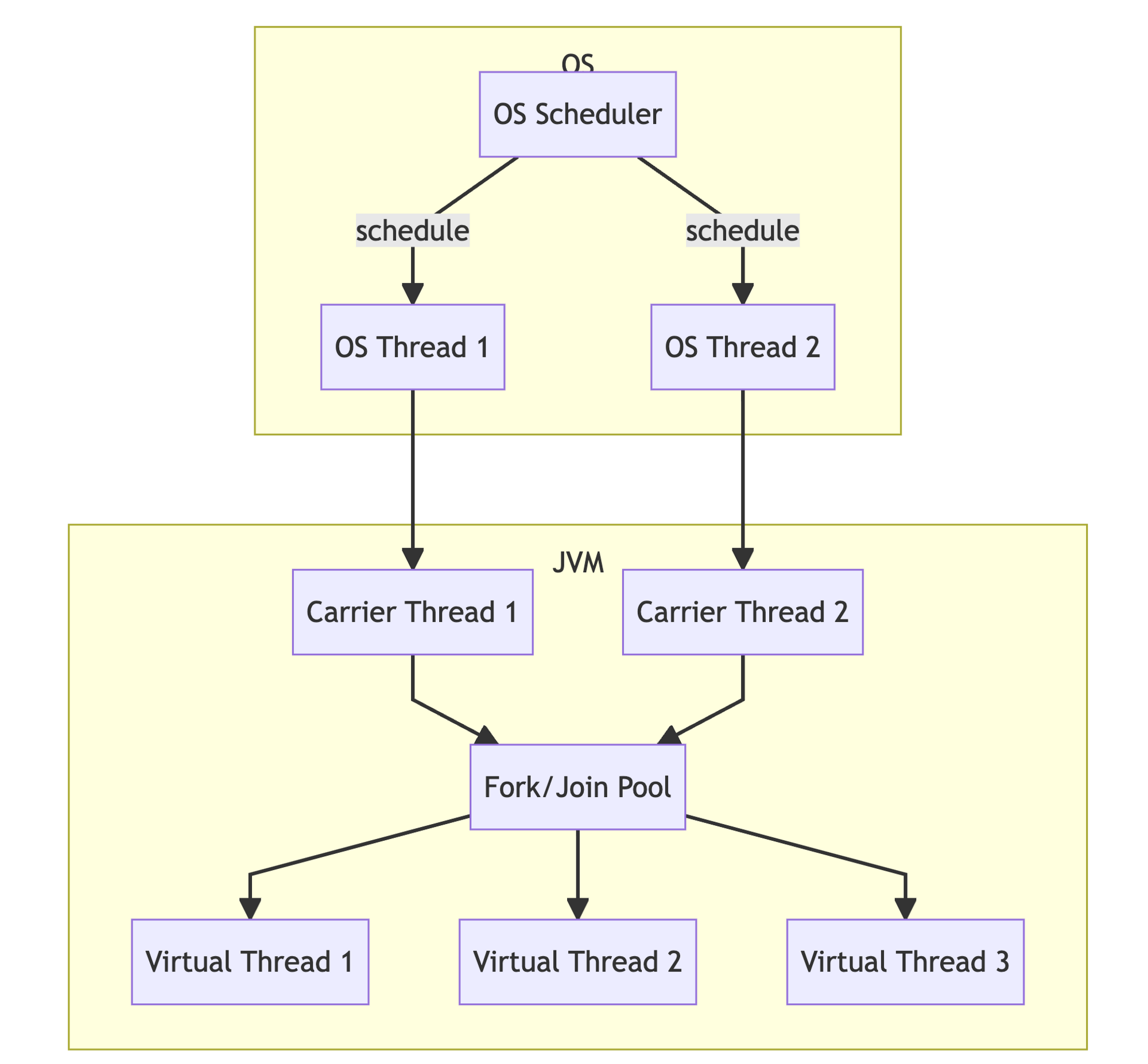
(출처: https://perfectacle.github.io/2022/12/29/look-over-java-virtual-threads/)- OS 쓰레드와 1대1 대응이 되는 carrier 쓰레드가 있고, 이들은 쓰레드 풀을 형성하여 ForkJoinPool에 submit 된 task를 virtual thread로 실행한다.
- virtual thread를 실행하기 위한 carrier thread는 CPU 코어 개수에 비례하여 JVM이 자동으로 생성한다.
- 한 carrier thread는 최대 1개의 virtual thread를 실행할 수 있다.
- virtual thread에서 blocking I/O가 발생하면 이를 실행하고 있던 carrier thread는 다른 virtual thread를 실행시킨다.
Why is virtual thread needed? (motivation)
What was the problem of JVM thread?
Before I go into virtual threads, I need to revisit classic threads or, what I will call them from here on out, platform threads.
The JDK implements platform threads as thin wrappers around operating system (OS) threads, which are costly, so you cannot have too many of them. In fact, the number of threads often becomes the limiting factor long before other resources, such as CPU or network connections, are exhausted.
In other words, platform threads often cap an application’s throughput to a level well below what the hardware could support.
- https://blogs.oracle.com/javamagazine/post/java-loom-virtual-threads-platform-threads
JVM 쓰레드는 OS 쓰레드를 얇게 감싸놓은 구조이다. 따라서 JVM 쓰레드를 늘리려면 OS 쓰레드가 늘어나야 하는데, OS 쓰레드를 추가하는 비용은 너무 높다. 얼마나 심각하냐면, CPU나 network connection 등 하드웨어가 제공하는 다른 리소스를 다 쓰기도 전에 JVM 쓰레드(= OS 쓰레드)의 수가 작업 성능의 병목이 될 때가 상당히 많다. OS 쓰레드는 생성도 느리고, 컨텍스트 스위칭도 느리고, 메모리도 많이 잡아먹는다.
위와 같은 문제를 해결하기 위해 virtual thread가 도입되었다.
What is the goal of virtual thread?
Goals
- Enable server applications written in the simple thread-per-request style to scale with near-optimal hardware utilization.
- Enable existing code that uses the
java.lang.ThreadAPI to adopt virtual threads with minimal change.- Enable easy troubleshooting, debugging, and profiling of virtual threads with existing JDK tools.
Non-Goals
- It is not a goal to remove the traditional implementation of threads, or to silently migrate existing applications to use virtual threads.
- It is not a goal to change the basic concurrency model of Java.
- It is not a goal to offer a new data parallelism construct in either the Java language or the Java libraries. The Stream API remains the preferred way to process large data sets in parallel.
몇 가지 중요한 키워드는 아래와 같다.
- hardware utilization을 최대한으로 끌어 올린다.
- 기존 JDK의 쓰레딩 모델에 대해 하위 호환을 지켜야 한다.
- 디버깅 / 프로파일링이 쉬워야 한다.
Why not coroutine? virtual thread vs. coroutine?
필자가 아는 coroutine이 kotlin coroutine 밖에 없어서, kotlin coroutine을 기준으로 설명한다.
coroutine도 위의 Overview에서 설명한 virtual thread와 비슷하게 blocking I/O가 발생한 시점에 제어권을 thread pool(dispatcher)에 yield 함으로써 소수의 쓰레드만으로도 다수의 작업을 처리할 수 있다. 그렇다면 왜 JDK는 다른 언어에 이미 많이 도입된 coroutine 대신 virtual thread라는 새로운 개념을 설계하고 도입했을까?
이는 JEP 444에 정확히 명시되어 있다.
Alternatives
- Add syntactic stackless coroutines (i.e., async/await) to the Java language. These are easier to implement than user-mode threads and would provide a unifying construct representing the context of a sequence of operations.
That construct would be new, however, and separate from threads, similar to them in many respects yet different in some nuanced ways. It would split the world between APIs designed for threads and APIs designed for coroutines, and would require the new thread-like construct to be introduced into all layers of the platform and its tooling. This would take longer for the ecosystem to adopt, and would not be as elegant and harmonious with the platform as user-mode threads.
Most languages that have adopted syntactic coroutines have done so due to an inability to implement user-mode threads (e.g., Kotlin), legacy semantic guarantees (e.g., the inherently single-threaded JavaScript), or language-specific technical constraints (e.g., C++). These limitations do not apply to Java.
의역을 많이 섞자면, function coloring 문제로 인해 기존 코드에 대한 하위 호환성이 거의 지켜지지 않아 adopting 기간이 매우 길어지기 때문에 coroutine을 사용하지 않았다고 한다.
그러면 왜 다른 언어는 virtual thread 대신 coroutine을 도입했는가? 언어마다 다양한 이유가 있는데,
- Kotlin - user-mode thread를 직접 구현할 수 없었다…라고 하는데, 아마 JVM에 실행을 의존하기 때문에 JVM에서 virtual thread를 지원하지 않는 한 자체적으로 구현할 수 없다는 의미로 보인다.
- JavaScript - 언어 설계 상 본질적으로 single-threaded에 adopting 된 구조여서 굳이 breaking change를 도입하지 않더라도 괜찮은 경우
- C++ - 언어에 한정된 기술적인 제약…이라고 하는데, C++을 사용하지 않아서 정확히 어떤 제약인지는 모르겠다.
추측을 하나 얹자면, coroutine의 경우 stack trace가 제대로 남지 않아(continuation 방식이므로 가장 마지막으로 yield한 시점 전의 stack trace가 전혀 남지 않는다) 디버깅이 어려운 문제도 있다. 이는 virtual thread의 non-goal 중 하나이다.
Internals
기본적인 동작 방식
- 여러 개의 carrier thread가 있고, 여기에 virtual thread를 ‘mount’ 시키면 carrier thread가 자신에게 mount 된 virtual thread을 실행하는 구조이다. mount란, carrier thread에 해당 carrier thread가 실행할 virtual thread를 배정하는 것을 의미한다.
- carrier thread가 virtual thread를 실행하는 동안 결국 두 쓰레드는 하나의 OS thread를 공유하는 셈인데, 이 사실이 코드 상으로는 드러나지 않는다. 다른 말로 하면, carrier thread와 이 carrier thread에서 실행되는 virtual thread는 서로 독립된 stack trace와 ThreadLocal을 가진다.
- mounting을 구현하기 위해 JDK는 내부적으로 virtual thread 실행을 위한 ForkJoinPool을 들고 있다. 이 ForkJoinPool의 사이즈는 기본적으로 CPU core의 개수를 따라가고, 시스템 프로퍼티를 통해 변경할 수 있다.
- 이 쓰레드풀은 common pool과는 독립적으로 구성된다.
- blocking I/O 등으로 인해 ‘unmount’된 virtual thread의 stack frame은 heap에 저장된다. 다시 mount 하고 싶을 때는 stack frame을 heap에서 읽어 stack으로 로딩하기만 하면 된다.
→ context switch가 OS 차원이 아니라 JVM 차원에서 이루어지기 때문에 훨씬 빠르다. - blocking이 끝나서 virtual thread의 이후 작업을 다시 실행할 수 있게 되면, blocking operation은 다시 virtual thread를 ForkJoinPool에 던진다. ForkJoinPool은 FIFO queue이므로, 해당 virtual thread는 자기 순서가 다가오면 다시 mount 되어 실행된다.
What is, and why ForkJoinPool?
일반적인 executorService는 한 task가 여러 task를 던지고 그 결과를 기다리는 식의 작업을 처리할 때 쓰레드 경합이 발생할 수 있다.
반면, ForkJoinPool은 work-stealing 한 특성을 가지고 있다.
As with any
ExecutorServiceimplementation, the fork/join framework distributes tasks to worker threads in a thread pool. T*he fork/join framework is distinct because it uses a work-stealing* algorithm. Worker threads that run out of things to do can steal tasks from other threads that are still busy.
- https://docs.oracle.com/javase/tutorial/essential/concurrency/forkjoin.html
예시를 통해 두 executorService의 동작 방식의 차이를 알아보자.
1 | fun main() { |
위 코드를 실행했을 때의 출력 결과는 아래와 같다.
1 | main task 1 started at Thread[ForkJoinPool-1-worker-1,5,main] |
executorService는 쓰레드가 부족해서 subtask 2-1을 실행하지 못한 반면, forkJoinPool은 work-stealing 방식으로 동작하기 때문에 subtask 1-1의 실행에 성공한 것을 확인할 수 있다. 따라서, ForkJoinPool은 하나의 task가 여러 subtask를 spawn하는 divide-and-conquer 방식의 코드를 적은 수의 thread로 지원하는 데 적합하다.
virtual thread에서 ForkJoinPool을 사용한 이유는, virtual thread 실행 시 위와 같이 thread pool 고갈로 인한 blocking을 방지하기 위함으로 보인다.
- 만약 일반적인 ForkJoinPool이 아닌 일반적인 executorService로 virtual thread를 구현했다면, 한 virtual thread에서 매우 많은 virtual thread를 실행하고 결과를 기다리면 carrier thread가 고갈되어 무한히 blocking 될 수 있다.
- 반면 위에서 보았듯, ForkJoinPool을 사용하면 work-stealing 방식으로 동작하기 때문에 이러한 blocking이 발생하지 않는다. 유저 입장에서는 virtual thread가 내부적으로 한정된 숫자의 carrier thread pool에 의해 실행된다는 내부 구현을 모르고, 새로운 thread가 생성되어 실행되는 것처럼 인식한다. 따라서 thread pool 고갈로 인한 blocking 문제가 발생해서는 안 된다. 그렇기 때문에 일반적인 executorService를 사용하면 안 되고, ForkJoinPool을 사용하는 것이 적합하다.
How does virtual thread yield on blocking call?
java.util.concurrent.LockSupport, java.net, java.nio.channels, java.io 등 blocking이 발생할 수 있는 JDK 코드를 재작성하여, blocking이 발생하는 경우 platform thread가 다른 일을 할 수 있도록 release 하고, blocking이 끝난 경우 virtual thread를 re-schedule한다.
Parking a virtual thread releases the underlying platform thread to do other work, and unparking a virtual thread schedules it to continue. This change to
LockSupportenables all APIs that use it (Locks,Semaphores, blocking queues, etc.) to park gracefully when invoked in virtual threads.
- https://openjdk.org/jeps/444#java-util-concurrent
이때 blocking call의 내부 구현은 대략 아래와 같은 흐름으로 이루어진다.
JDK는 blocking call이 발생하는 경우,
unmount()호출 뒤Continuation.yield()를 호출한다.1
2
3
4
5
6
7
8
9
10
11
12
13
14// JDK core code
private boolean yieldContinuation() {
boolean notifyJvmti = notifyJvmtiEvents;
// unmount
if (notifyJvmti) notifyJvmtiUnmountBegin(false);
unmount();
try {
return Continuation.yield(VTHREAD_SCOPE);
} finally {
// re-mount
mount();
if (notifyJvmti) notifyJvmtiMountEnd(false);
}
}native method가 많아서 정확한 동작은 모르겠으나(debugger도 제대로 동작하지 않는다… finally 문에 debug point를 찍어둬도 멈추질 않는다), 몇 가지 실험에 따르면
Continuation.yield()함수는 park에 성공할 경우 virtual thread의 stack frame을 저장하고, 제어 흐름을 carrier thread에 넘겨주며, virtual thread의 실행을 멈추는 것으로 보인다. park에 실패할 경우(e.g. synchronized block 안에서 실행; 아래의 pinning 문제 섹션 참고)에는 즉시 false를 리턴한다.blocking이 끝나야 하는 시점에 다른 곳에서 unpark()를 호출한다.
unpark를 호출하는 방법에는 여러가지가 있는데, 예를 들어
Thread.sleep()은 park 하기 전 unparking을 scheduling 해둔다(scheduleUnpark()).1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
void parkNanos(long nanos) {
assert Thread.currentThread() == this;
// complete immediately if parking permit available or interrupted
if (getAndSetParkPermit(false) || interrupted)
return;
// park the thread for the waiting time
if (nanos > 0) {
long startTime = System.nanoTime();
boolean yielded;
Future<?> unparker = scheduleUnpark(this::unpark, nanos);
setState(PARKING);
try {
yielded = yieldContinuation();
} finally {
assert (Thread.currentThread() == this)
&& (state() == RUNNING || state() == PARKING);
cancel(unparker);
}
// park on carrier thread for remaining time when pinned
if (!yielded) {
long deadline = startTime + nanos;
if (deadline < 0L)
deadline = Long.MAX_VALUE;
parkOnCarrierThread(true, deadline - System.nanoTime());
}
}
}다시
yieldContinuation()함수의return Continuation.yield(VTHREAD_SCOPE);라인부터 실행이 시작된다.mount()가 호출되어 carrier thread에 자기 자신을 mounting 한 뒤, 남은 작업을 실행한다.
하위호환성
- virtual thread는 coroutine 등의 asynchronous style로 동작하지 않는다. 대신 virtual thread는 기본적으로
java.lang.Thread의 확장 클래스이다. 따라서 JDK가 기존부터 오랜 기간 제공하던 많은 모니터링 도구들에 대한 하위호환이 완벽하게 지원된다. e.g. Java debugger, JDK Flight Recorder(JFR) 등. - ThreadLocal 역시 virtual thread 별로 격리된 공간이 제공된다. 다만, virtual thread는 기존 platform thread와는 달리 수백만 개까지 생성되는 시나리오를 지원하는 것이 목적인데, 무분별하게 ThreadLocal을 남용하면 메모리를 많이 잡아먹을 수 있으니 조심해야 한다.
- virtual thread에서의 blocking call은 대부분의 상황에서 carrier thread를 block 시키지 않지만, 일부 상황에서는 block 시킨다. 이런 케이스에 해당하는 구현이 있다면 구현을 수정한 뒤 virtual thread를 도입해야 한다. carrier thread를 block 시키는 상황에 대한 자세한 설명은 pinning 문제 참고.
이슈
pinning 문제
native method call, synchronized block 호출 등 virtual thread가 unmount 되기를 기대하는 상황 중 일부에서는 virtual thread가 carrier thread에 계속 할당된 상태로 남아 있어서 carrier thread를 block 하는 이슈가 있다. 이러한 상황에 처한 virtual thread의 상태를 pinning 상태라고 부른다.
이를 해결하려면 synchronized block 대신 ReentranceLock 등을 사용해야 한다.
마무리
개인적으로는 Kotlin coroutine보다 JDK virtual thread의 설계가 마음에 드는데, 크게 두 가지 포인트에서 더 낫다고 생각한다.
- 하위호환성 - 하위호환을 지키는 것은 생각보다 매우 중요하다. coroutine이나 여타 유사한 시스템을 도입할 때 개인적으로 가장 어렵다고 느끼는 것은 function coloring 문제로 인해 기존 코드를 상당히 많이 바꿔야 한다는 점이다. virtual thread를 도입할 때는 pinning 문제만 고려하면 되기 때문에 기존 코드를 거의 수정하지 않고도 매우 손쉽게 공짜 점심을 얻을 수 있다.
- stack trace 유지 - Reactive programming이나 coroutine의 경우 stack trace가 제대로 보이지 않아서 디버깅이 피곤했었는데, virtual thread는 yield 후 re-mount 되어 재실행되더라도 stack trace가 제대로 유지되기 때문에 이러한 피곤함이 발생하지 않을 것이다.
추가적으로, virtual thread의 장점이라기보다는 언어 자체에서 지원하냐 마냐의 차이로 인해 발생하는 이점인데, unexpected blocking call으로 인한 위험이 거의 없을 것이라는 점도 마음에 든다. Kotlin coroutine 입장에서는 좀 억울할 수 있지만, virtual thread의 경우 JDK 차원에서 blocking call을 yield 하도록 재구현했기 때문에 unexpected blocking call로 인해 thread가 오래 blocking 될 걱정을 하지 않아도 된다.
Refs
- https://perfectacle.github.io/2022/12/29/look-over-java-virtual-threads/
- https://blogs.oracle.com/javamagazine/post/java-loom-virtual-threads-platform-threads
- https://openjdk.org/jeps/444
- https://blog.rockthejvm.com/ultimate-guide-to-java-virtual-threads/
- https://docs.oracle.com/javase/tutorial/essential/concurrency/forkjoin.html