
개요
Kotlin coroutine의 structured concurrency의 동작 방식을 다시 살펴보자.
- parent가 어떤 이유로든 취소되면, parent의 모든 children이 취소된다.
- child에서 exception이 던져져서 취소되면, exception은 parent로 전파되어서 parent를 취소시킨다. child가 명시적인 취소로 인해 취소되면 parent로 취소가 전파되지 않는다.
이 글은 Kotlin coroutine에서 위와 같은 structured concurrency를 어떻게 구현했는지를 설명하는 글이다. coroutine의 API와 동작 방식에 대해 어느 정도 익숙하다는 전제 하에 작성된 글이어서, 글의 내용이 이해가 되지 않는다면 Kotlin coroutine proposal과 공식 가이드 문서를 먼저 읽는 것이 도움이 될 것이다.
이 글에서 참고한 코드는 Kotlin 1.5.30 버전과 kotlinx coroutines core 1.5.2 버전을 사용하였다.
structured concurrency를 위한 트리 구성
structured concurrency의 동작 방식을 보면, coroutine이 내부적으로 트리 구조(부모-자식)의 형태로 관리가 되고 있음을 추측할 수 있다. 이 트리 구조가 무엇으로 구성되어 있고, 또 어떤 방식으로 구성되는지 알아보자.
실제 내부 구현을 까보면, structured concurrency를 구현하기 위한 기반 요소는 크게 두 가지이다.
Job(interface) - structured concurrency에서 가장 중요한 요소로, 보통 coroutine과 1대1로 형성되어 위에서 언급한 트리 구조를 형성한다. 각 job은 취소의 전파에 따라 자신과 대응되는 coroutine을 적절히 취소시킨다.CoroutineScope(interface) - CoroutineScope.coroutineContext에는 coroutine의 실행을 위한 여러가지 정보가 담기지만, 가장 중요한 것은 coroutine의Job을 저장하는 것이다.Job은 하나의CoroutineContext.Element이고,CoroutineScope.coroutineContext에는 반드시Job이 포함되어 있어야만 한다. 이는 아래와 같이 javadoc에도 명시되어 있다.“…By convention, the context of a scope should contain an instance of a job to enforce the discipline of structured concurrency with propagation of cancellation.”(CoroutineScope.kt)
이제 coroutine 시작 시 Job의 트리가 어떤 과정을 통해 구성되는지 알아보자. 아래는 각종 coroutine 클래스의 기반 구현을 제공하는 AbstractCoroutine의 구현 중 일부이다.
1 |
|
coroutine이 실행될 때 발생하는 일을 간단하게 정리하면 다음과 같다.
- coroutine 객체가 생성될 때, constructer param으로 “부모의 coroutine context”(
parentContext)를 받는다. parentContext에서 부모의 Job을 빼온다(parentContext[Job]).- 자신의 job을 부모의 child로 붙인다(
val handle = parent.attachChild(this)).
즉, 자식 coroutine이 생성될 때 자신의 Job을 부모의 Job에 자식으로 붙이는 방식을 통해 트리 구조가 형성된다.
위의 동작 자체는 간단하지만, 이 코드만 봐서는 structured concurrency의 자세한 동작에 대해 알 수 없는 중요한 요소가 두 가지 있다.
- “부모의 coroutine context”인
parentContext에는 어떤 값이 주입되는가? -parentContext[Job]에 무엇이 담겨 있느냐에 따라서 부모Job이 무엇인지가 달라지고, 결과적으로Job트리의 구성이 달라질 수 있다. Job트리에서 각Job의 실행 순서는 어떻게 결정되는가? - 예를 들어launch {}는 자신의 내부에서 실행된 coroutine의 종료를 기다리지 않는 반면,coroutineScope {}는 자신의 내부에서 실행된 coroutine이 모두 종료될 때까지 다음 코드를 실행하지 않는다. 둘의 동작 방식의 차이는 어디서 비롯되는가?
이 두 가지에 본격적으로 알아보기 전에, Kotlin에서 coroutine과 Job, CoroutineScope과의 관계를 어떻게 추상화했는지를 살펴보도록 하자. 내부 코드를 읽고 이해하는 데 큰 도움을 준다.
AbstractCoroutine - coroutine은 CoroutineScope이며 Job이다
coroutine 클래스의 기반 클래스인 AbstractCoroutine의 구현을 보자.
1 | public abstract class AbstractCoroutine<in T>( |
코드를 보면 AbstractCoroutine이 Job과 CoroutineScope 인터페이스를 모두 구현하고 있음을 알 수 있다. 이것의 의미는 아래와 같다.
CoroutineScope- coroutine은 자기 자신이 scope가 되어 자신의 code block 안에서 자식 coroutine을 실행할 수 있다. 또한, 자신의 coroutine context를 자식 coroutine에게 전달할 수 있다(e.g. 위에서 본parentContext주입 등).Job- coroutine은 structured concurrency를 위한 트리의 노드 그 자체이다.
즉, 위에서 언급했던 coroutine의 structured concurrency를 위한 모든 동작을 사실은 coroutine이 전부 수행하고 있는 것이다. 이 추상화는 Job 객체나 CoroutineScope 객체를 별도로 관리해야 할 필요를 없애기 때문에 코드를 훨씬 단순하게 만든다. 예를 들어, 위에서 보았던 val handle = parent.attachChild(this) 코드를 보자. AbstractCoroutine은 별도의 Job을 만들어서 parent에 전달하는 대신, 자기 자신(this)을 parent에게 붙일 수 있다.
어차피 coroutine에 모든 역할을 때려 넣을 거면 애초부터 Job과 CoroutineScope이라는 개념을 만들지 않아도 되었던 것 아니냐고 생각할 수 있다. 그럴 수도 있는데, 이러한 구현은 복잡한 시스템이 자기 자신을 보다 분명하게 표현하도록 도와준다. Job과 CoroutineScope라는 인터페이스 없이 AbstractCoroutine에 모든 구현을 때려 넣었다면 structured concurrency를 위한 tree라는 개념과 coroutine 실행의 scope이라는 개념이 코드 상에 제대로 드러나지 않았을 것이고, 각 개념을 달성하기 위한 코드가 한데 뒤섞여 코드를 이해하기 매우 어려웠을 것이다. Job과 JobSupport mixin, 그리고 CoroutineScope을 통해 명시적으로 개념을 분리하고, 이를 구현의 편의를 위해 하나로 다시 합친 덕분에 코드가 훨씬 깔끔해졌다.
coroutine tree의 구성
이제 본론으로 돌아가서, 우선 parentContext가 무엇인지, 그리고 coroutine 실행 시 coroutine tree(이제부터 Job tree 대신 coroutine tree라고 하겠다)가 어떻게 구성되는지로 돌아가보자.
Kotlin에서 제공하는 primitive coroutine builder에는 크게 3가지가 있는데, 아래와 같이 분류할 수 있다.
CoroutineScope의 extension function -launch {},async {}등- suspending function -
withContext {},coroutineScope {}등 - root coroutine builder -
runBlocking {}등
위 3가지 종류의 coroutine builder는 구현이 서로 다르기 때문에, 각각의 구현을 살펴보아야 한다.
CoroutineScope의 extension function인 coroutine builder
launch {}와 async {}는 반환하는 객체가 Job인지 Deferred인지를 제외하고는 구현이 비슷해서, launch {}의 구현만 살펴보겠다.
1 | public fun CoroutineScope.launch( |
- 새 coroutine에 사용할 context를 만든다.
- 1의 coroutine context를 사용하여 새로운
StandaloneCoroutine객체를 만든다. - 2의 coroutine을 시작한다.
여기서 parentContext, 즉 (4)에는 어떤 값이 담겨 있는가? (2)를 보면 newContext가 parentContext로 넘어오는 것을 알 수 있다. 이제 newCoroutineContext() 구현을 살펴보자.
1 |
|
launch {} 호출 시 context param에 아무것도 넘겨주지 않는다면, (5)에서 더해지는 두 context의 내용물은 다음과 같다.
coroutineContext-launch {}의 receiverCoroutineScope의coroutineContextcontext-EmptyCoroutineContext
즉, parentContext는 launch {}의 receiver CoroutineScope의 coroutineContext이다.
그렇다면 “launch {}의 receiver CoroutineScope“은 어떻게 결정되는가? 이는 (3)의 start()가 어떻게 구현되어 있는지를 통해 확인할 수 있다.
1 | /* AbstractCoroutine.start()의 구현 */ |
(6)을 보면 (3)에서 전달한 coroutine이 block의 receiver CoroutineScope이 되는 것을 알 수 있다. 즉, launch {}의 인자로 넘긴 block의 receiver는 launch {}로 인해 생성된 coroutine 그 자체이다. 부모 coroutine이 이 구현과 동일한 방법으로 시작되었다고 가정하면, “launch {}의 receiver CoroutineScope”는 부모 coroutine이 된다. 따라서 parentContext는 부모 coroutine의 context가 된다.
이제 결론까지 마지막 한 가지만 남았다. 부모 coroutine의 context[Job] 에는 무엇이 들어 있는가? 이는 AbstractCoroutine의 구현을 보면 알 수 있다.
1 |
|
(7)의 val context: CoroutineContext = parentContext + this에서 this는 Job으로의 this이다. 그리고 (8)에서 coroutineContext에 이 context를 그대로 노출하는 것을 알 수 있다. 즉, coroutineContext[Job]에는 coroutine 자기 자신이 들어 있다.
이제 위의 내용들을 다시 정리해보자.
- 자식 coroutine은
parentContext[Job]에 자기 자신을 자식으로 붙인다. - 자식 coroutine은
parentContextparam으로launch {}의 receiverCoroutineScope.coroutineContext을 받는다. launch {}의 receiverCoroutineScope는 부모 coroutine이다.AbstractCoroutine.coroutineContext[Job]에는 자기 자신이 담겨 있다.
따라서, launch {}로 coroutine을 실행하면 부모 - 자식 관계 그대로 coroutine tree가 형성된다. 결론은 매우 직관적이고, 간단하다.
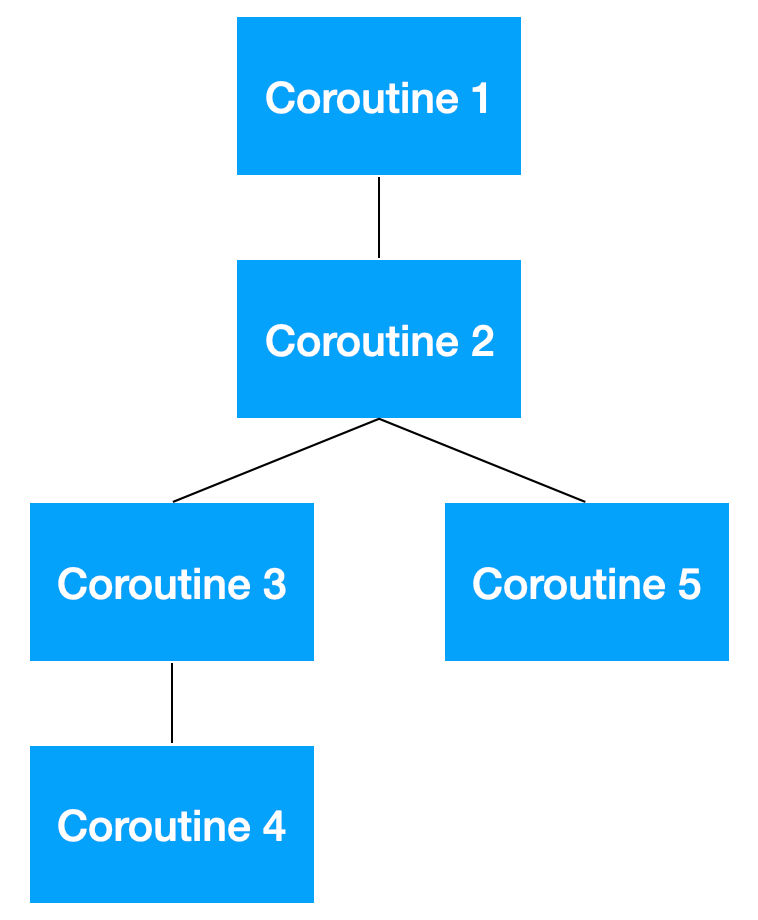
예시를 통해 확인해보자. 아래는 coroutine 코드 예제와 해당 예제를 coroutine tree로 치환한 것이다.
1 | runBlocking { /* coroutine 1 */ |
suspending function인 coroutine builder
다음은 suspending function인 withContext {}와 coroutineScope {}이다. 둘 역시 구현이 비슷한데, 여기서는 구현이 간단한 coroutineScope {}만 살펴보겠다.
1 | /* Note: CoroutineScope의 extension function이 아님을 기억하자. */ |
핵심 구현 자체는 매우 간단하다.
- coroutine을 만든다.
- coroutine을 실행한다.
(1), (3), (4)를 보면 uCont.context가 parentContext가 됨을 알 수 있다. 그렇다면 uCont는 무엇인가? suspendCoroutineUninterceptedOrReturn()의 구현을 보자.
1 | /** |
구현이 intrinsic이라 볼 수는 없지만, javadoc을 통해 uCont가 부모 coroutine임을 유추할 수 있다.* 즉, launch {}와 동일하게 부모 coroutine의 context를 parentContext로 받는다. 따라서, coroutineScope {}에서도 launch {}와 동일하게 부모 - 자식 관계를 그대로 유지하며 coroutine tree가 구성된다.
* 이 부분을 보다 잘 이해하기 위해서는 1. Kotlin coroutine이 내부적으로 CPS로 동작하는 메커니즘과 2. AbstractCoroutine이 Continuation의 역할도 맡는다는 것을 알아야 한다. 이 부분을 설명하기에는 글이 너무 길어질 듯하여 생략한다.
runBlocking {}의 동작
그렇다면 runBlocking {}과 같은 함수로 인해 실행되는 root coroutine은 어떤 Job의 자식으로 실행되는가? runBlocking {}의 구현을 보자.
1 |
|
보면 newContext가 GlobalScope.newCoroutineContext()에 의해 만들어지는 것을 알 수 있다. 이 함수의 구현은 위에서 살펴본 적이 있다.
1 |
|
이 두 함수의 구현을 토대로 역추적을 해보면, newContext에는 eventLoop element 밖에 없는 것을 알 수 있다. 즉, Job이 없는 것이다. 실제로 runBlocking {}으로 만들어진 BlockingCoroutine의 parent를 디버거로 찍어 보면 null임을 알 수 있다. 대신, runBlocking {}으로 만들어진 BlockingCoroutine은 eventLoop의 종료로 관리된다. 이는 BlockingCoroutine.joinBlocking() 함수의 구현을 보면 알 수 있다.
1 |
|
while문 안 쪽을 잘 보면 isCompleted가 true일 때, 즉 event loop의 queue가 비었을 때 종료됨을 알 수 있다. 즉, runBlocking {}으로 실행된 coroutine은 부모 coroutine 없이(따라서 부모 Job 없이) 실행된다.
coroutine tree에서 각 coroutine이 실행되는 순서
이제 coroutine tree가 어떻게 구성되는지를 확인했으니, 만들어진 tree를 기반으로 coroutine이 어떤 순서로 실행되는지를 알아보자.
여기서도 tree 구성 방식 때와 유사하게 coroutine builder를 두 가지로 나누어서 보아야 한다.
CoroutineScope의 extension function -launch {},async {}등- suspending function -
withContext {},coroutineScope {}등
CoroutineScope의 extension function - fire-and-forget
launch {}나 async {}는 fire-and-forget 방식으로 동작한다. 아래의 launch {} 구현을 보자.
1 | public fun CoroutineScope.launch( |
함수 구현에 blocking call이 없고, launch {} 자체가 suspending function이 아니기 때문에 suspending point도 없다. 따라서 coroutine을 실행시킨 뒤에 멈추지 않고 이후의 코드를 실행한다. 이 coroutine이 실행되는 것을 기다리거나 적절히 종료시키는 것은 이 coroutine의 조상 중 누군가의 책임이 된다. 예를 들어, runBlocking {}을 사용한다면 runBlocking {}의 event loop가 해당 책임을 지게 된다.
suspending function - 자식 coroutine이 끝날 때까지 suspend
한편, withContext {}나 coroutineScope {}은 suspending function이다. 이 둘은 자식 coroutine이 모두 종료될 때까지 기다리도록(suspend 하도록) 구현되어 있다.
1 | public suspend fun <R> coroutineScope(block: suspend CoroutineScope.() -> R): R { |
여기서 (1)의 구현을 보자.
1 | internal fun <T, R> ScopeCoroutine<T>.startUndispatchedOrReturn(receiver: R, block: suspend R.() -> T): Any? { |
필자도 정확한 메커니즘을 파악하진 못했지만, 함수 내부의 javadoc의 (2)를 보면 children을 기다리고 있으면 suspend 한다는 내용이 언급되어 있다. 이를 신뢰한다면 coroutineScope {}은 자식 coroutine이 모두 종료될 때까지 suspend 되는 것을 알 수 있다. withContext {} 역시 ScopeCoroutine이나 ScopeCoroutine을 상속받은 DispatchedCoroutine을 사용하므로 coroutineScope {}와 동일하게 동작함을 알 수 있다.
정리
이 글에서 알아본 내용을 정리하면 다음과 같다.
- coroutine ==
CoroutineScope==Job - structured concurrency를 구현하기 위해 coroutine을 실행할 때 job의 tree(== coroutine의 tree)를 만들어 관리한다.
- coroutine 내에서 coroutine builder(
launch {},async {},coroutineScope {},withContext {})를 통해 coroutine을 실행하면 부모 - 자식 형태 그대로 coroutine tree가 생성된다.runBlocking {}은 특수하게 parentJob없이 실행되고, 대신 event loop를 통해 자기 자신과 자식 coroutine의 실행을 추적하고 관리한다. launch {}와async {}로 실행된 coroutine은 별다른 실행 순서가 없다. 반면,coroutineScope {},withContext {}로 실행된 coroutine은 자식 coroutine이 모두 종료될 때까지 suspend 된다.