
작년 11월 중순부터 12월 중순까지 나는 타다 EKS 클러스터의 버전업 작업을 맡아서 진행했다. 타다 EKS 클러스터를 바닥부터 한땀한땀 띄워보면서 타다 백엔드 시스템이 무엇으로 구성되어 있고, 또 어떻게 동작하는지에 대해 정말 많이 배웠다. 그 때 배운 지식을 잊어버리기 전에 정리해보려고 한다.
모니터링 아키텍처와 metrics-server
개요
쿠버네티스의 모니터링 아키텍처는 쿠버네티스가 어떤 방식으로 각종 메트릭을 수집하고 사용하는지에 대한 아키텍처이다. 그리고 metrics-server는 모니터링 아키텍처의 한 요소이다.
동작 방식
모니터링 아키텍처에 대해 이야기하기 전에, 우선 메트릭의 분류에 대해 짚고 넘어가야 한다. 쿠버네티스는 메트릭을 core system metrics / non-core system metrics / service metrics의 3종류로 나누어서 본다. 각각의 분류와 정의는 다음과 같다:
- system metrics - 쿠버네티스가 어플리케이션과 무관하게 일반적으로 수집할 수 있는 메트릭. e.g. 노드나 컨테이너의 cpu & memory 사용량 등.
- core metrics - system metrics 중 쿠버네티스의 내부 동작에 필요한 메트릭. e.g. horizontal pod autoscaler(hpa)가 사용할 메트릭.
- non-core metrics - system metrics 중 core metrics가 아닌 메트릭.
- service metrics - 어플리케이션에서 직접 정의한 메트릭. e.g. 500 에러율 등.
위의 메트릭의 정의를 바탕으로, 쿠버네티스의 모니터링 아키텍처는 총 두 가지 메트릭 파이프라인을 정의한다.
- core metrics pipeline - core metrics을 수집하는 파이프라인
- monitoring pipeline - 나머지 메트릭을 수집하는 파이프라인
이렇게 분리한 이유는 쿠버네티스의 핵심 컴포넌트가 다른 3rd-party 모니터링 시스템에 의존하지 않게 만들기 위함이다.
core metrics pipeline은 수집해야 하는 메트릭이 core metrics 한 가지이기 때문에 비교적 간단하게 설계되었다. core metrics pipeline에서의 각 컴포넌트의 역할을 적으면 아래와 같다:
- 메트릭 소스: kubelet
- 메트릭 수집: metrics-server
- 메트릭 서빙: metrics-server (=master metrics API)
한편, 쿠버네티스 모니터링 아키텍처는 monitoring pipeline이 어떤 메트릭을 어떻게 수집할지에 대해서는 정의하지 않는다. 이는 모니터링 솔루션을 구현하는 쪽의 자유이다. 다만 이렇게 수집된 API를 쿠버네티스 핵심 컴포넌트에 제공할 때(e.g. hpa with custom metrics)는 stateless adaptor를 구현해야 한다고 명확하게 정의해놓았다.
아래는 모니터링 솔루션으로 cAdvisor + Prometheus를 사용할 때의 전반적인 아키텍처로, 쿠버네티스 모니터링 아키텍처 문서의 사진에서 설명에 불필요한 부분을 적절히 잘라낸 것이다.
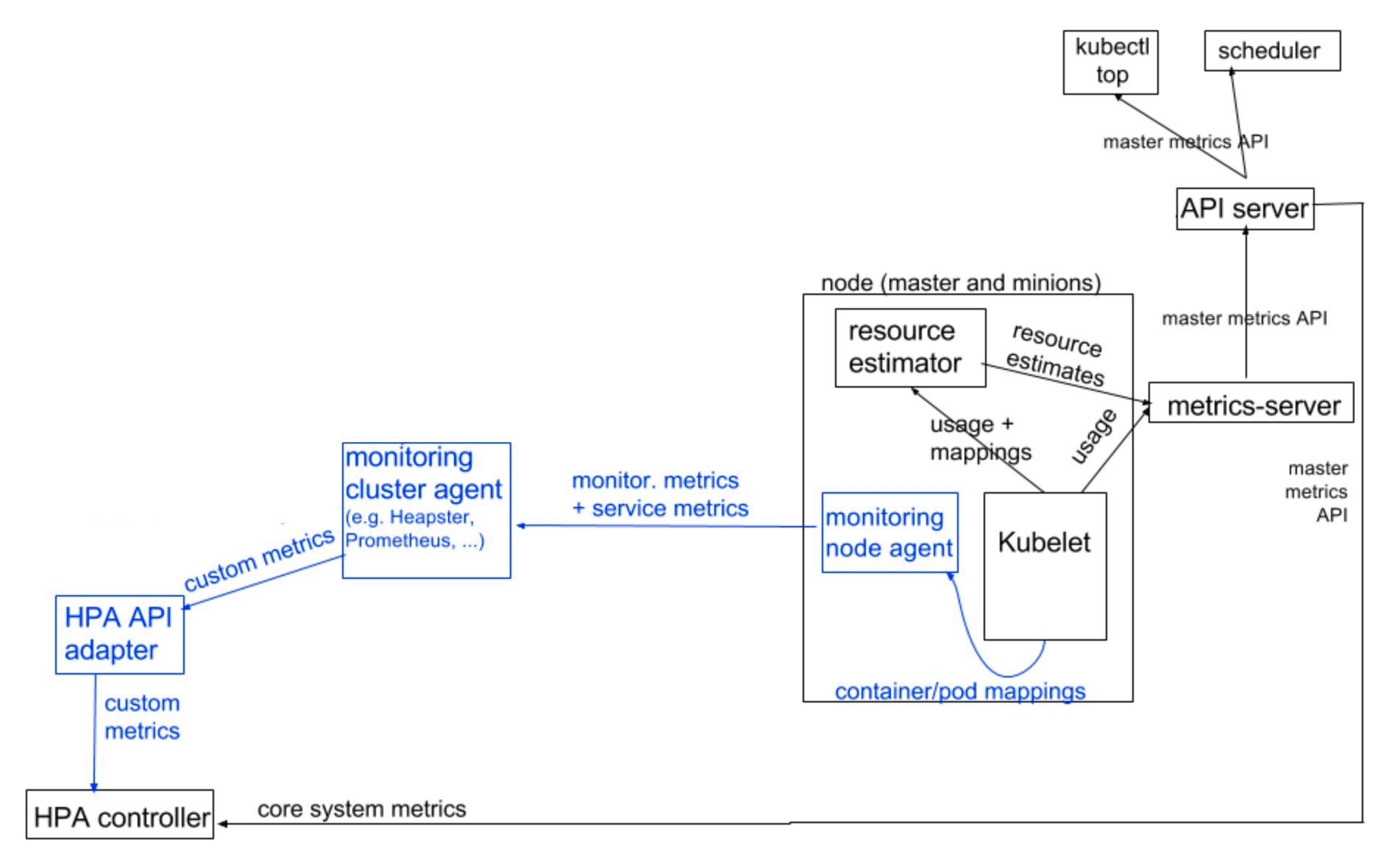
참고로, EKS로 쿠버네티스 클러스터를 구성하면 metrics-server가 설치되어 있지 않은 상태이므로 hpa를 사용하고 싶다면 별도로 metrics-server를 띄워야 한다.
Prometheus Operator
개요
prometheus operator는 오픈소스 모니터링 솔루션인 Prometheus를 kubernates native하게 배포하고 관리할 수 있는 도구이다(“kubernetes native”라는 뜻은 쿠버네티스의 API를 사용하여 쿠버네티스 클러스터 위에서 동작한다는 뜻인 것 같다). 뿐만 아니라 prometheus operator를 통해 alertmanager나 grafana와 같은 모니터링 시스템을 추가적으로 배포할 수 있다.
동작 방식
prometheus operator는 helm으로 설치되는데, prometheus operator 팟과 다양한 커스텀 리소스가 함께 배포된다. prometheus-operator는 이 커스텀 리소스에 대한 controller 역할을 한다.
prometheus operator의 커스텀 리소스 중 핵심적인 요소는 딱 두 가지이다.
- Prometheus - 말 그대로 Prometheus를 추상화한 것이다. 리소스의 정의에 Prometheus에 대한 구성이 들어간다. e.g. Prometheus 팟의 replica 개수, persistent volume 구성, 어떤 어플리케이션을 모니터링할지 등.
prometheus operator는 Prometheus 리소스에 대해 두 가지 역할을 한다. 첫 번째는 Prometheus 팟을 띄우는 것인데, 이는 StatefuleSet을 배포함으로써 이루어진다. 두 번째 역할은 Prometheus 팟이 어떤 어플리케이션을 모니터링해야 하는지를 알려주는 것이다. 이는 뒤에서 살펴볼 ServiceMonitor 항목에서 더 자세히 살펴볼 것이다. ServiceMonitor - 어플리케이션이 어떻게 모니터링되어야 하는지를 추상화한 것이다. ServiceMonitor를 정의할 때 필요한 것은 크게 두 가지이다. 첫 번째는 모니터링 대상이 되는 Service 리소스에 대한 label selector이고, 두 번째는 모니터링을 할 수 있는 endpoint이다.
위에서 Prometheus를 구성할 때 어떤 어플리케이션을 모니터링할지 지정할 수 있다고 했는데, 이 때 지정하는 게 바로 “어떤 ServiceMonitor가 target이 되는지”에 대한 rule이다. prometheus operator는 이 rule을 기반으로 Prometheus의 모니터링 대상이 되는 ServiceMonitor를 scan하여 해당 정보를 Secret으로 배포한다. 그리고 이 Secret을 Prometheus StatefulSet에 마운트한다. 이런 방식으로 Prometheus 팟은 자신이 모니터링할 Service가 무엇인지 알 수 있다.
이외에도 Alertmanager, PrometheusRule, PodMonitor 등 다양한 커스텀 리소스가 있는데, 이번 글에서는 설명을 생략하겠다.
아래 그림은 prometheus operator의 동작 방식을 그림으로 표현한 것이다.
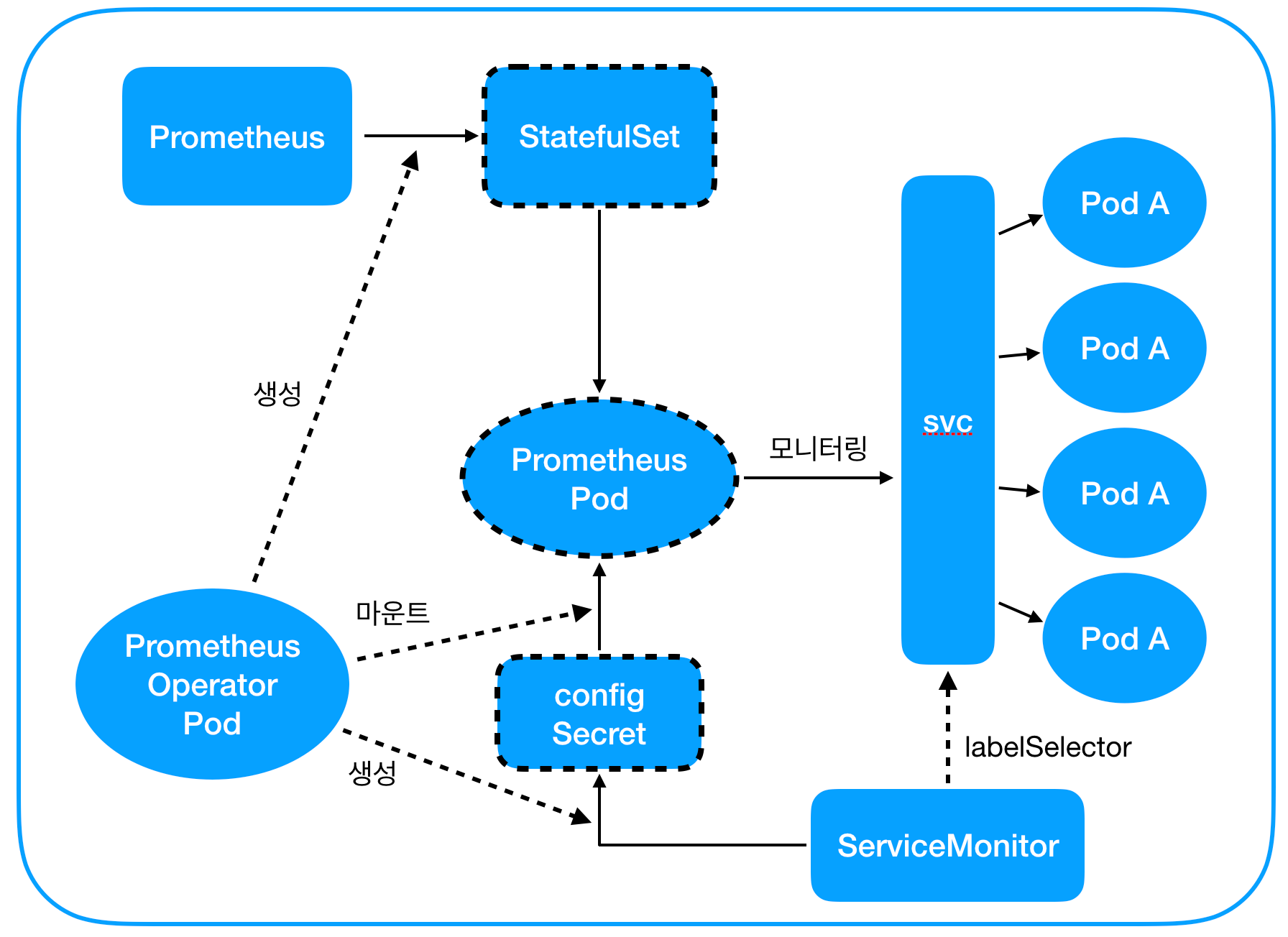
- Prometheus 리소스를 적절히 구성하여 배포한다.
- prometheus operator가 1의 Prometheus 리소스에 대해 Prometheus StatefulSet을 배포한다. 이는 다시 Prometheus 팟을 배포한다.
- ServiceMonitor를 배포한다.
- 3의 ServiceMonitor가 1의 Prometheus의 모니터링 대상에 해당할 경우, prometheus operator가 3의 ServiceMonitor 정보를 Secret으로 배포한 후 Prometheus 팟에 마운트한다.
- Prometheus 팟이 4에서 마운트된 정보를 바탕으로 Service를 모니터링한다.
Cluster Autoscaler
개요
cluster autoscaler는 node를 scale out/in 하기 위해 사용하는 쿠버네티스 컴포넌트이다. 구체적으로 다음과 같은 상황에 scale out/in 한다:
- scale out: 리소스 부족으로 인해 노드에 배치될 수 없는 팟이 존재할 경우
- scale in: 특정 노드의 팟을 모두 다른 노드로 옮겨서 노드를 제거할 수 있는 상태가 오래 지속되는 경우
동작 방식
이 글에서는 AWS에서 쿠버네티스 클러스터를 띄우는 경우에 대해서만 소개한다.
cluster autoscaler의 동작 방식에서 중요한 것은 크게 두 가지인데, 1. 컴퓨팅 리소스가 부족하거나 남는지를 판단하는 로직과 2. node를 새로 띄우거나 없애는 방법이다. 이 중 1번은 개요에서 간략히 설명하였다.
AWS 환경에서 클러스터를 운영하는 경우, 2번은 EC2 Auto Scaling Group(ASG)의 크기를 조절함으로써 이루어진다. cluster autoscaler는 ASG에 사용되는 인스턴스 타입을 보고 인스턴스 한 대당 얼마만큼의 CPU / memory / GPU를 사용할 수 있는지를 추정한다. 이 추정치를 바탕으로 적절한 개수의 노드를 새로 띄우거나 없앤다. 이러한 scaling은 ASG의 min / max capacity 범위 내에서 이루어진다.
위와 같은 동작이 가능하려면 cluster autoscaler에게 두 가지 요소가 필요하다. 1. AWS 리소스에 대한 적절한 접근 권한이 있어야 하고, 2. scale out/in의 대상이 되는 ASG가 무엇인지를 알 수 있어야 한다.
1번을 위한 한 가지 방법은 쿠버네티스 클러스터에 AWS secret을 배포하는 것인데, 이 방법은 credential 교체가 어려우므로 권장되지 않는다. cluster autoscaler 문서가 추천하는 방법은 IAM roles for Service Account(IRSA)를 활용하는 방법이다. IRSA는 쿠버네티스 service account와 AWS IAM role을 연관짓는 방법으로, 이 방법을 사용하면 명시적으로 credential을 배포하지 않아도 팟이 특정 IAM role에 assume 할 수 있다.
* IRSA의 동작 방식은 이 글에서는 기술하지 않는다.
2번에 대해 cluster autoscaler 문서가 추천하는 방법은 autodiscovery 기능을 사용하는 것이다. cluster autoscaler를 설치할 때 -node-group-auto-discovery 옵션을 주면 해당 옵션의 값을 태그로 가진 ASG를 자동으로 찾아서 scaling의 대상으로 삼는다. 이 때 여러 개의 ASG를 cluster autoscaler에게 등록할 수도 있다. 이를 그림으로 정리하면 아래와 같다.
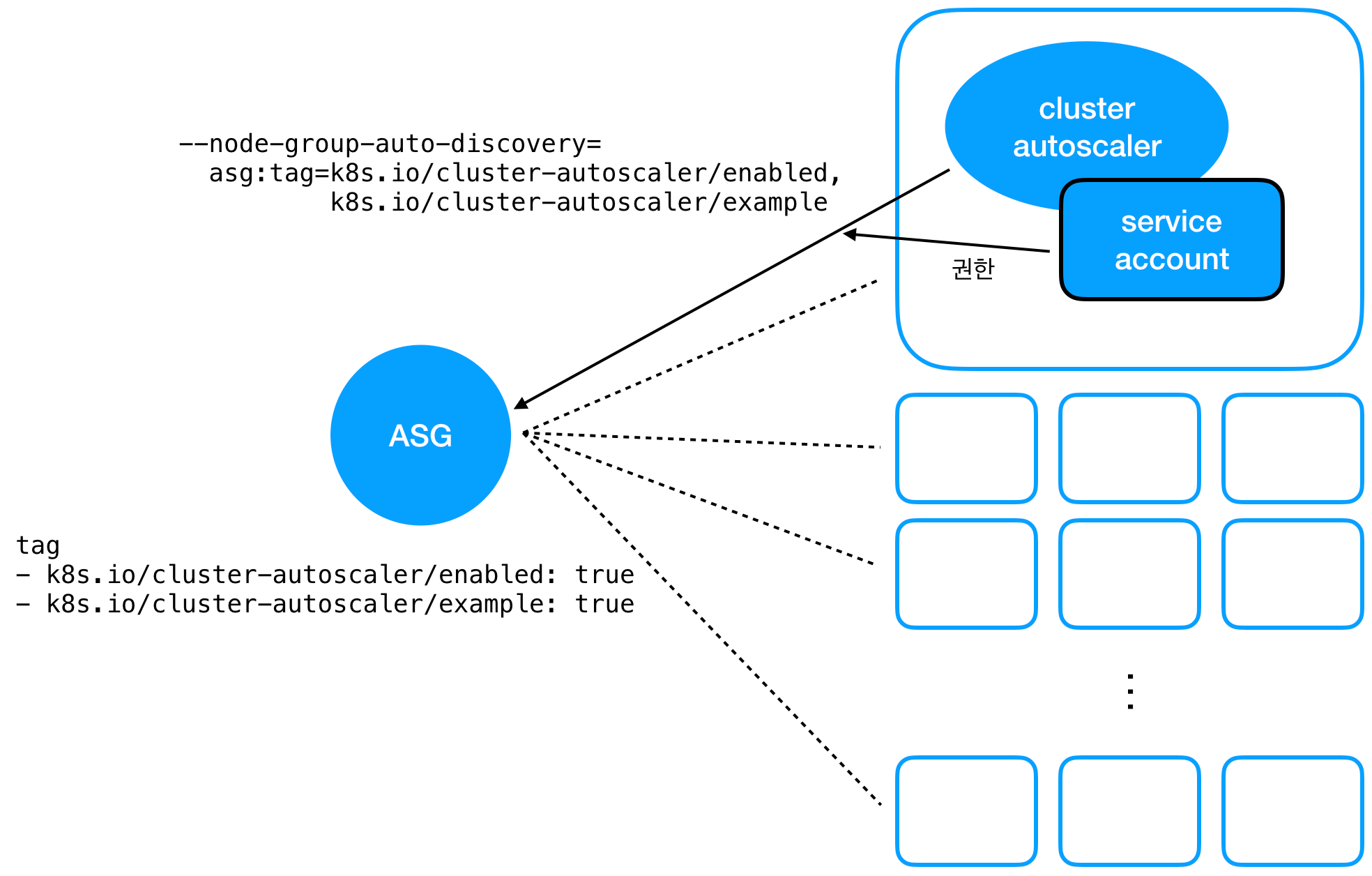
참고로, ASG에 특정한 태그를 달아서 노드 label이나 taint 정보를 cluster autoscaler에게 전달할 수도 있다.
- label 예시:
k8s.io/cluster-autoscaler/node-template/label/foo: bar - taint 예시:
k8s.io/cluster-autoscaler/node-template/taint/dedicated: NoSchedule
예를 들어 두 개의 ASG를 cluster autoscaler에 등록하는데 하나에는 nodegroup=A라는 label을, 다른 하나에는 nodegroup=B라는 label을 달았다고 해보자. 이 때 nodeSelector가 nodegroup=A인 팟이 리소스 부족으로 인해 뜨지 못하면 cluster autoscaler는 자동으로 nodegroup=A label이 달린 ASG를 scale out 한다.
nginx ingress controller
개요
쿠버네티스의 아키텍처에서 중요한 요소 중 하나는 컨트롤러이다. 컨트롤러는 하나 이상의 쿠버네티스 리소스 타입을 watch하며, current state를 이 리소스 타입의 desired state에 맞추는 역할을 담당한다. 예를 들어, Job object를 배포하면 쿠버네티스에 내장된 Job 컨트롤러가 이 object에 기술된 spec에 맞춰 팟을 실행시킨다.
Job 컨트롤러처럼 이미 내장된 컨트롤러도 있지만, 기본으로 구현되어 있지 않은 컨트롤러도 있다. 바로 Ingress 컨트롤러이다. 왜 Ingress 컨트롤러가 내장이 안 되어 있는지는 검색해보아도 잘 나오지 않는데, 개인적인 생각으로는 다른 리소스와 달리 Ingress 리소스는 쿠버네티스 내부의 네트워킹 방식이 아니라 외부에도 영향을 미치기 때문인 것 같다. 만약 쿠버네티스에 nginx Ingress 컨트롤러가 내장되어 있었다면 모든 쿠버네티스 유저는 외부 트래픽을 받는 서버로 nginx를 사용하도록 강제되었을 것이다. 이렇게 사용자가 특정 기술을 강제적으로 사용해야 하는 제약을 없애기 위해 Ingress 컨트롤러를 자유롭게 선택할 수 있도록 남겨둔 게 아닐까 추측해본다.
아무튼, 쿠버네티스는 Ingress 컨트롤러를 내장하고 있지 않아서 직접 설치해서 사용해야 하는데, 이 때 사용할 수 있는 Ingress 컨트롤러 구현체는 다양하다. 그 중에서도 nginx를 활용하는 것이 바로 nginx Ingress 컨트롤러이다.
동작방식
기본적인 동작 방식은 간단하다. nginx를 띄우고, Ingress 리소스에 대응되는 nginx configuration을 적용하는 것이다. 특정 path로 들어오는 트래픽을 특정 Service의 ClusterIP로 라우팅하거나, secret으로 배포된 인증서를 사용하여 TLS termination을 수행하도록 nginx를 띄우는 것과 nginx configuration을 업데이트하는 것은 모두 nginx Ingress 컨트롤러 팟의 역할이다. 이 팟은 Deployment object에 의해 띄워진다.
여기에 추가로, 외부에서 들어오는 트래픽을 nginx Ingress 컨트롤러 팟으로 보내주는 Service 리소스가 필요하다. 이 Service는 LoadBalancer나 NodePort 타입 중 하나인데, 쿠버네티스 클러스터를 어떤 방식으로 구성하느냐에 따라서 둘 다 사용할 수 있다. 사실 LoadBalancer Service를 만들면 NodePort Service가 자동으로 만들어지기 때문에 거의 비슷한 동작 방식이라고 할 수 있다.
요약하면, nginx Ingress 컨트롤러는 적절한 configuration으로 nginx를 띄우는 nginx Ingress 컨트롤러 Deployment object + 외부에서 들어오는 트래픽을 nginx Ingress 컨트롤러 팟으로 보내주는 Service로 구성되어 있다. 전체적인 네트워크 트래픽의 흐름을 그림으로 표현하면 다음과 같다.
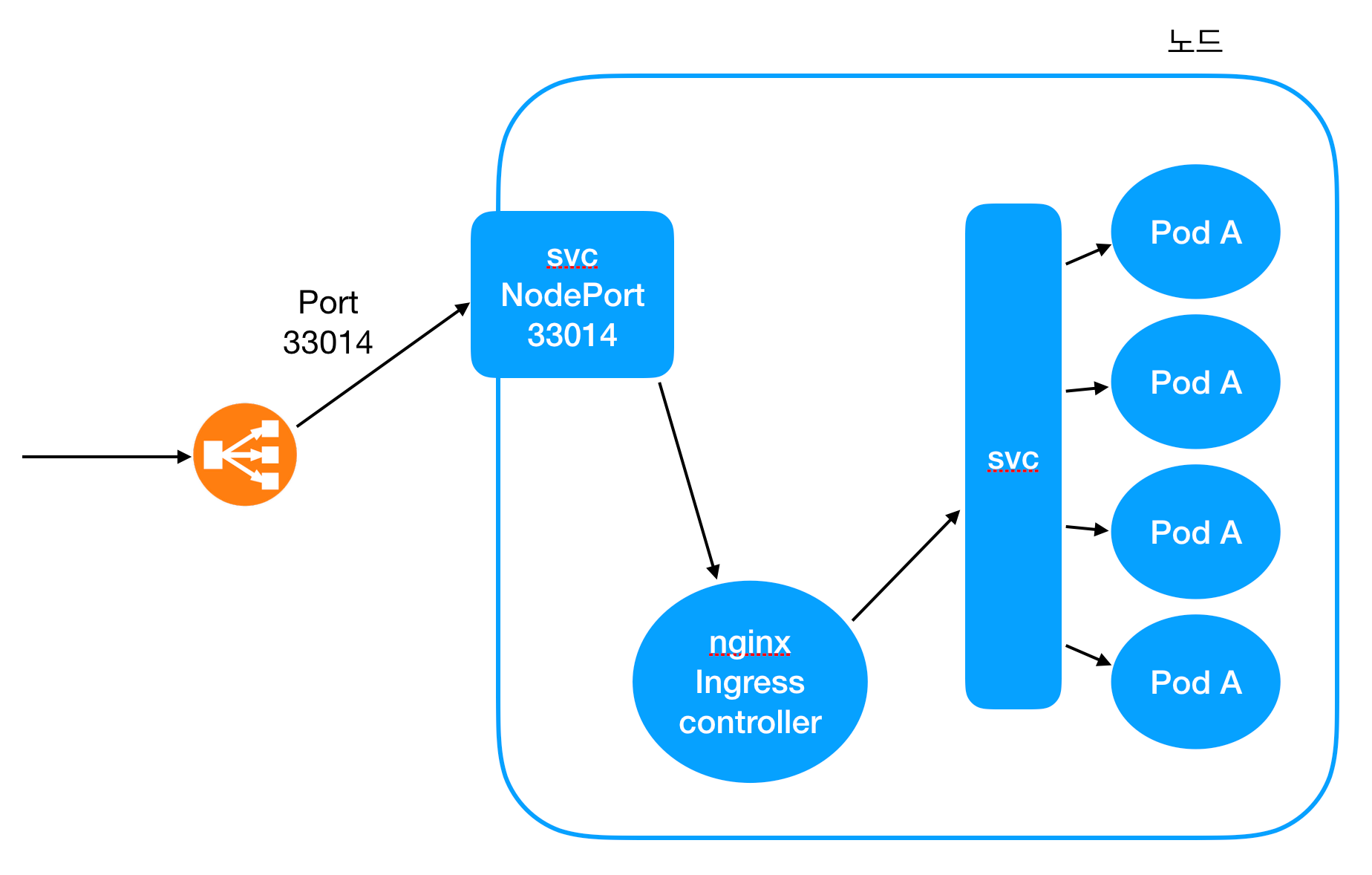
- 외부에서 트래픽이 특정 포트로 들어온다.
- 이 트래픽은 NodePort Service에 의해 nginx Ingress 컨트롤러의 팟으로 리다이렉트 된다.
- nginx는 Ingress를 기반으로 생성된 configuration을 바탕으로 다른 Service로 트래픽을 리다이랙트한다.
- Service는 대상 pod에게 트래픽을 분산시켜준다.
* Service의 동작 방식 - Service가 어떻게 특정 pod으로 트래픽을 리다이렉트 시켜주는지 - 는 이 글에서는 기술하지 않는다.
kube2iam
개요
kube2iam은 쿠버네티스 환경에서 노드가 아니라 팟 단위로 권한을 제어하기 위해 탄생한 툴이다. 쿠버네티스에서는 한 노드에 다양한 팟이 섞여서 뜨는데, 일반적으로 각 팟은 서로 다른 AWS 권한을 필요로 한다. 팟 A는 SQS만 접근하면 되고 팟 B는 Kinesis stream에만 접근하면 되는 식이다. 만약 kube2iam이 없다면 노드에 SQS와 Kinesis stream 접근 권한을 모두 줄 수밖에 없고, 따라서 팟 A와 팟 B는 둘 다 SQS와 Kinesis에 접근할 수 있게 될 것이다. kube2iam은 정확히 이 문제를 해소해준다.
동작방식
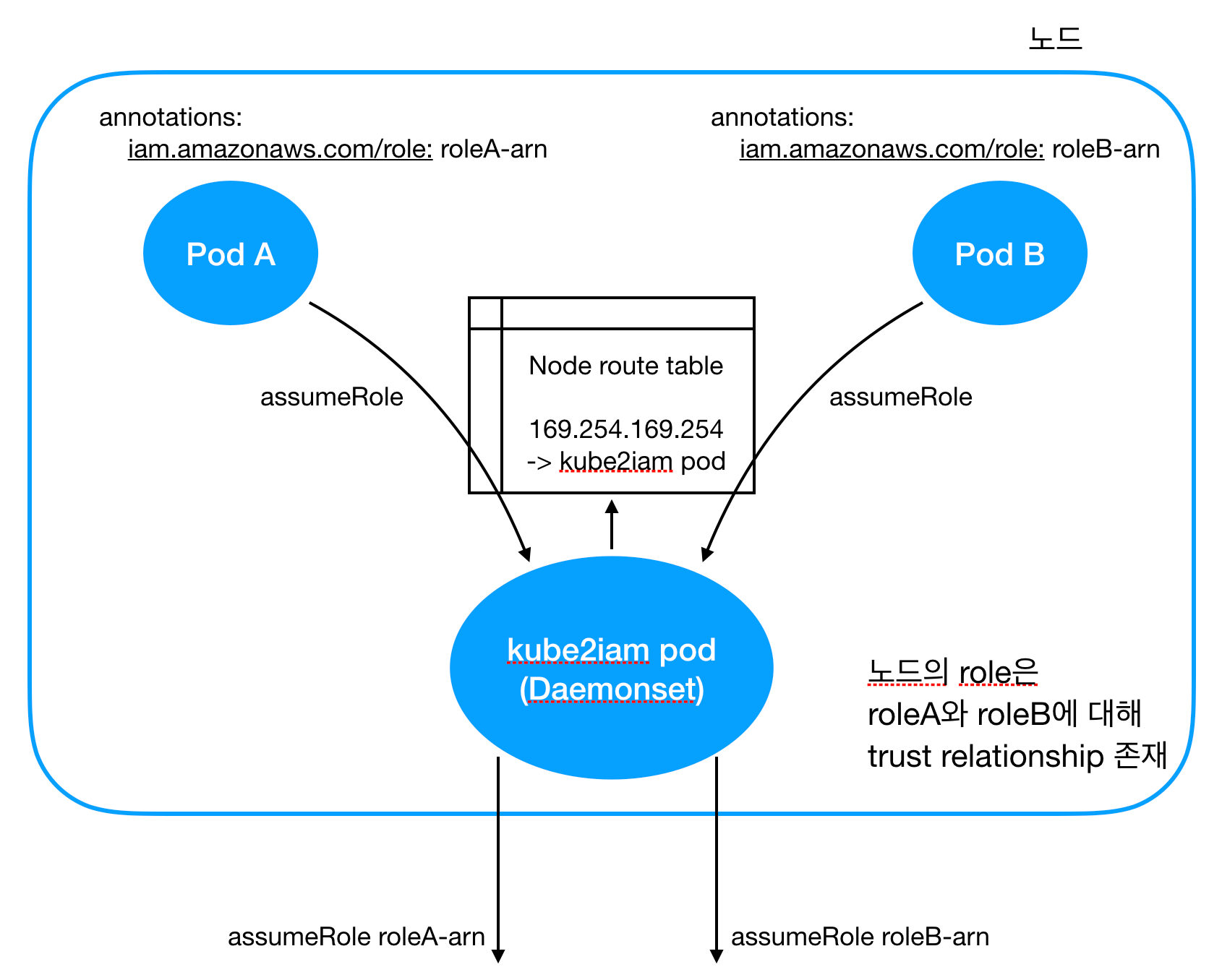
- kube2iam 팟이 노드에 설치되면 EC2 metadata API를 호출하는 트래픽을 kube2iam 팟으로 리다이렉팅하는 route table rule을 노드의 route table에 설치한다.
- 팟 A와 팟 B를 설치할 때 각 팟이 assume 하고 싶은 role을 팟의 annotation으로 달아준다.
- 각 팟에서 assumeRole을 하려고 하면 kube2iam 팟이 그 트래픽을 캡쳐해서 팟의 어노테이션에 적힌 role로 assume 한 뒤 그 credential을 각 팟에 돌려준다.
이 때 주의해야 하는 사항은 다음과 같다.
- 각 서비스 팟보다 kube2iam 팟이 먼저 뜨고 route table에 rule이 깔려야 제대로 동작한다.
- 노드는 각 팟이 assume 하려는 모든 role에 대해 assume 할 수 있도록 trust relationship이 설정되어 있어야 한다.
amazon-vpc-cni
개요
쿠버네티스 공식 홈페이지에 따르면, 쿠버네티스의 네트워크 구성은 다음의 2가지 사항을 요구한다.
- 노드의 팟은 NAT 없이 모든 노드의 모든 팟과 통신할 수 있다.
- 노드의 agent(e.g. system daemon, kubelet)는 해당 노드의 모든 팟과 통신할 수 있다.
이를 위해 쿠버네티스는 모든 팟에 고유한 IP 주소를 한 개씩 할당한다. amazon vpc cni 플러그인은 AWS 위에 구성된 쿠버네티스 클러스터에서 이를 달성하기 위한 플러그인이다.
동작방식
모든 팟에 고유한 IP 주소를 할당하기 위해 amazon vpc cni 플러그인은 아주 단순한 방법을 사용한다. 바로 elastic network interface(ENI)의 secondary IP 주소를 사용하는 것이다. 팟이 새롭게 뜨면 아직 사용하지 않고 있는 secondary IP 주소를 해당 팟에 할당한다.
이로 인해 재밌는 특성이 생기는데, 바로 각 노드 당 띄울 수 있는 팟의 수에 제한이 생긴다는 것이다. 더 이상 노드에 secondary IP 주소를 추가할 수 없으면 팟도 띄울 수 없다. 따라서 한 노드에 띄울 수 있는 팟의 숫자는 정확히 (노드에 붙일 수 있는 ENI의 수) x (각 ENI에 할당할 수 있는 secondary IP 주소의 수)가 된다.
팟에 IP 주소를 할당하는 것만으로는 불충분하다. 팟과 팟, 노드와 팟의 통신이 원할히 이루어지기 위해서는 각 노드의 route table이 제대로 구성되어 있어야 한다. 구체적으로, 팟에 할당된 IP는 팟의 네트워크 인터페이스로 redirect 하는 룰이 필요하다. (출처: amazon-vpc-cni github repository)
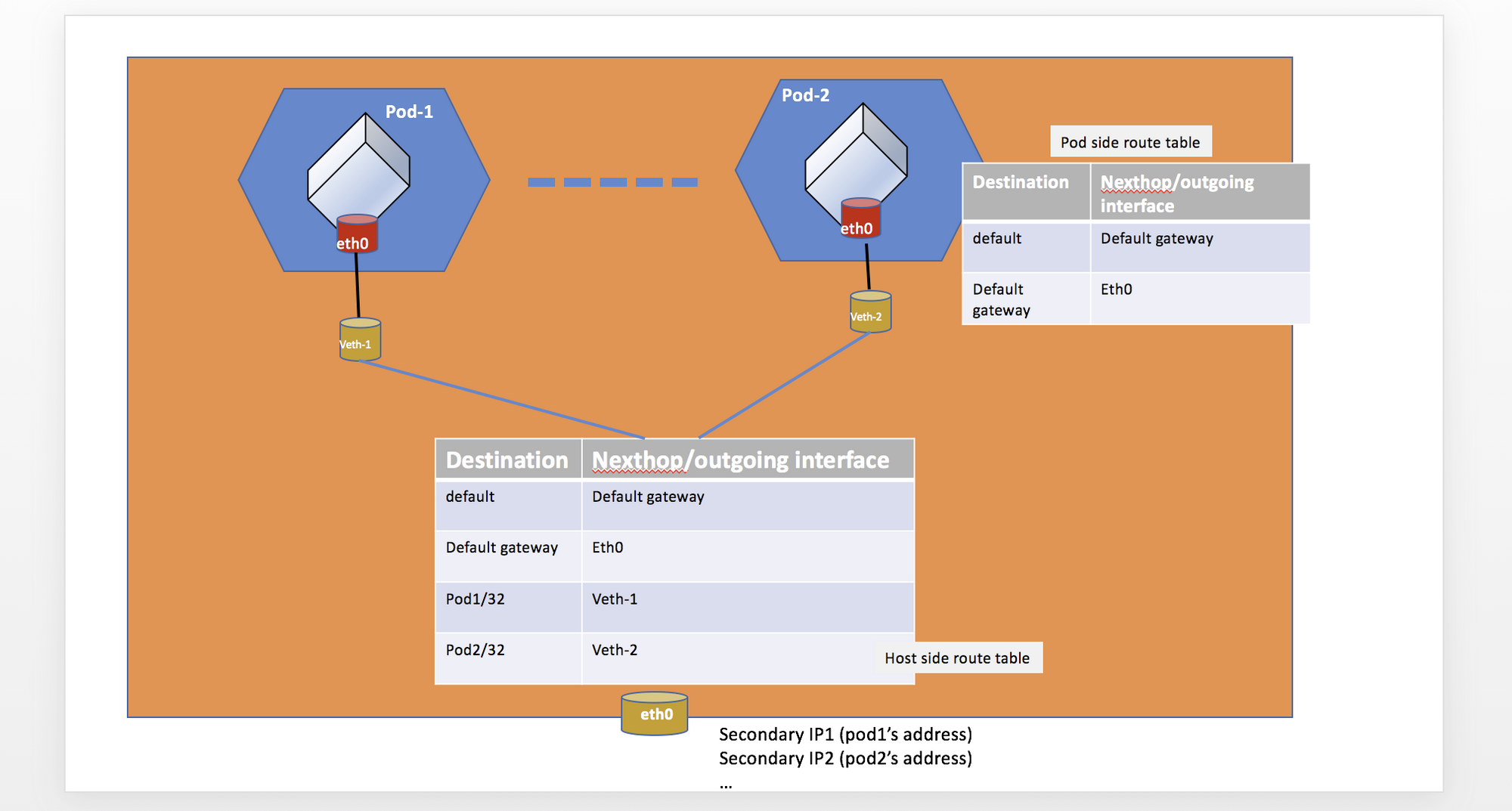
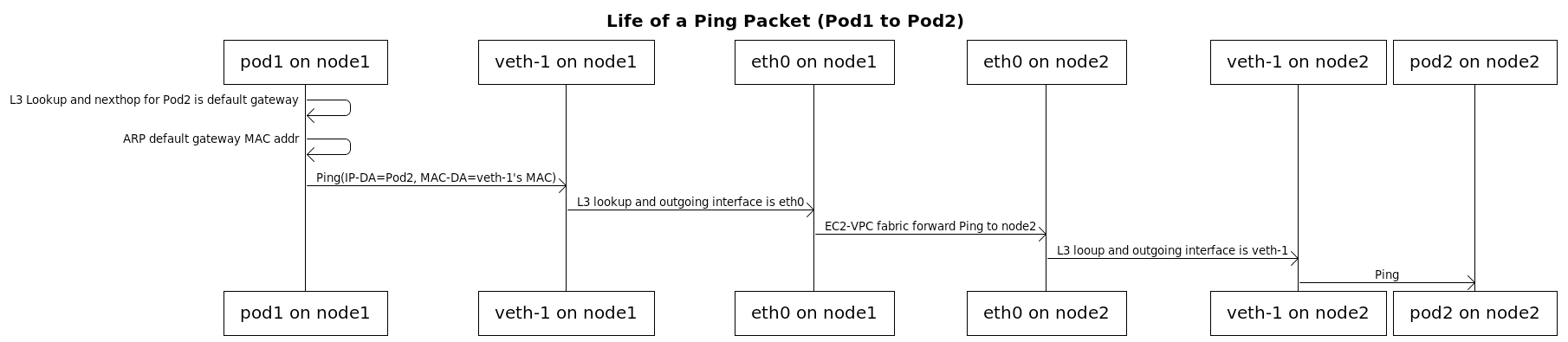
위 사진을 보면, 노드의 route table에 팟1의 IP로 들어온 트래픽은 veth-1, 즉 팟1으로 리다이렉트를 하고 있다. 마찬가지로 팟2의 IP로 들어온 트래픽은 veth-2, 즉 팟2로 리다이렉트를 한다. 위 상황에서 팟1 → 팟2로의 트래픽 이동을 그림으로 나타내보면 아래와 같다. (출처: amazon-vpc-cni github repository)
cert-manager
개요
cert-manager는 쿠버네티스 클러스터에서 인증서를 쉽게 관리하기 위한 툴이다. 쿠버네티스에서 인증서를 활용하기 위해서는 인증서를 Secret object로 배포해야 한다. 또한, 인증서는 유효기간이 지나기 전에 주기적으로 교체해줘야 한다. cert-manager는 이러한 역할을 CRD(custom resource definition)를 활용하여 자동으로 수행해준다.
동작 방식
cert-manager는 크게 3개의 컴포넌트로 구성되어 있다. 바로 Issuer/ClusterIssuer, Certificate, CertificateRequest이다. 이들은 모두 CRD에 의해 정의된다.
- Issuer/ClusterIssuer - certificate authority를 나타내는 리소스이다. Issuer는 특정 namespace에 한정되어 있고, ClusterIssuer는 그렇지 않다는 차이점이 있다. 이 두 리소스에는 누가 어떻게 인증서를 발급할지에 대한 정보가 저장되어 있다. 예를 들어, 쿠버네티스 클러스터에 미리 배포해놓은 self-signed certificate를 가지고 인증서를 발급하는 가짜 issuer를 만들 수도 있고(아래 예시), Let’s Encrypt와 같은 진짜 CA에게 인증서 발급을 위임할 수도 있다. 아래는 cert-manager 홈페이지에 나와 있는 예시이다.
1 | apiVersion: cert-manager.io/v1 |
- Certificate - 말 그대로 인증서를 나타내는 리소스이다. Certificate 리소스를 정의할 때는 인증서를 발급할 Issuer/ClusterIssuer, 인증서의 인증 대상이 되는 도메인, 그리고 생성된 인증서를 저장할 Secret의 이름을 적어야 한다. 참고로 Certificate는 특정 namespace에 국한된 리소스이다. 즉, 여러 namespace에서 사용하고 싶다면 각 namespace마다 Certificate 리소스를 배포해줘야 한다. 아래는 cert-manager 홈페이지에 나와 있는 예시이다.
1 | apiVersion: cert-manager.io/v1 |
- CertificateRequest - 인증서 발급 요청, 즉 csr을 나타내는 리소스이다. Certificate가 배포되면 자동으로 생성된다. 어떤 Issuer/ClusterIssuer에게 요청할지와 csr 내용을 base64 encode한 값이 담겨 있다. 아래는 cert-manager 홈페이지에 나와 있는 예시이다.
1 | apiVersion: cert-manager.io/v1 |
마지막으로, CRD라면 당연히 custom resource를 위한 컨트롤러가 있어야 할 것이다. cert-manager를 설치하면 Deployment object에 의해 컨트롤러 팟이 뜬다. 이 컨트롤러가 위의 세 가지 리소스를 관찰하며 인증서를 발급/갱신, 저장해준다.
전체적인 그림은 다음과 같다.
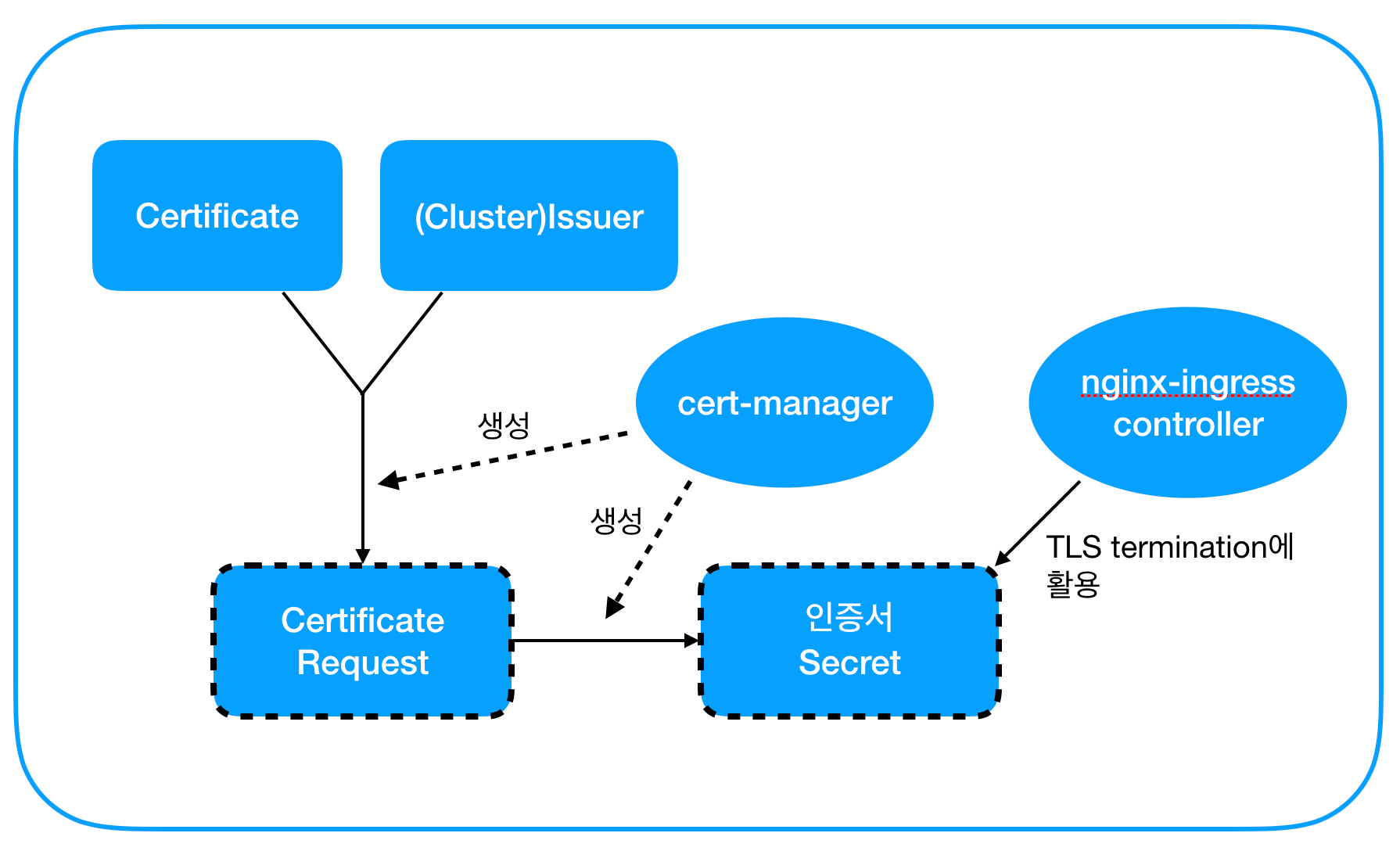
- cert-manager를 배포한다.
- Issuer/ClusterIssuer를 배포한다. (Issuer를 사용할 경우 특정 namespace에만 배포됨을 유의)
- 원하는 namespace에 Certificate를 배포한다.
- cert-manager가 CertificateRequest를 생성한다.
- cert-manager가 CertificateRequest를 바탕으로 인증서를 발급하여 Secret으로 저장한다.
- 다른 pod이 인증서를 활용한다. (e.g. nginx Ingress 컨트롤러의 TLS termination 등)
마무리하며
위에서 설명한 기술들은 쿠버네티스에 한정된 기술 스택이지만, 각각의 개념 자체는 모든 서비스를 운영하는 데에 필요할 것이다. 모니터링, 서버의 autoscaling, 보안 정책, 네트워킹, 인증서 관리, 그리고 이 글에서는 생략한 service discovery나 federation을 통한 인증 등. 이번 경험으로 익힌 지식은 앞으로 서버를 개발하고 운영하는 데에 큰 도움이 될 것이다.
출처
- https://github.com/kubernetes/community/blob/master/contributors/design-proposals/instrumentation/monitoring_architecture.md
- https://github.com/prometheus-operator/prometheus-operator/blob/master/Documentation/design.md
- https://github.com/kubernetes/autoscaler/tree/master/cluster-autoscaler/cloudprovider/aws
- https://kubernetes.github.io/ingress-nginx/how-it-works/
- https://github.com/jtblin/kube2iam
- https://github.com/aws/amazon-vpc-cni-k8s/blob/master/docs/cni-proposal.md
- https://cert-manager.io/docs/