
개요
나는 주로 필요에 의해서만 새로운 기술을 배우는 편인데, 최근에 Kubernetes를 사용할 일이 생겨서 드디어 배우고 싶던 Kubernetes를 공부하게 되었다.
그런데 공부하면 할수록 Kubernetes는 내가 지금까지 주워들었던 컨테이너 오케스트레이션 툴의 개념과 잘 맞지 않았다. 이 때문에 Kubernetes의 각 workload의 역할이 무엇인지, 그리고 kubectl에 넘겨주는 YAML 파일이 왜 그렇게 복잡한지 잘 이해할 수 없었다.
그러던 와중 오라클의 웨비나에서 강인호님이 발표하신 “Microservice, From beginner to Advanced”을 듣고 Kubernetes가 어떠한 아키텍처를 가지고 있는지를 배우게 되었다. 그렇게 Kubernetes의 동작 방식을 이해하고 나니 Kubernetes의 각 workload가 왜 필요하고, 왜 YAML 파일이 그런 식으로 구성되었는지를 쉽게 이해할 수 있었다.
그래서 이번 글에서는 강인호님의 세미나를 글로 정리하고, 여기에 살짝 내 코멘트를 덧붙여보았다.
* 이 글에서 말하는 컴포넌트는 API server, Controller Manager 등과 같이 실제로 Kubernetes 시스템을 이루는 각 부분을 의미하고, workload는 Pod, Deployment, ReplicaSet과 같은 개념을 뜻한다. 이는 Kubernetes 공식 홈페이지에서 사용하는 용어를 따온 것이다.
Kubernetes의 Input은 Action이 아니라 Desired State이다
Kuberenetes 공식 홈페이지의 다큐멘테이션을 읽으면 유독 desired state라는 단어가 많이 등장한다. 이는 Kubernetes를 이해하는 데에 있어서 핵심적인 부분이다.
docker에서 컨테이너를 띄우는 명령어는 $docker run <image name>이다. 이 커맨드는 docker engine에게 “이 이미지를 베이스로 컨테이너를 하나 띄워주세요”라는 한 가지 action을 지시하는 것이다.
반면, Kubernetes는 그렇지 않다. 우리는 Kubernetes에게 “어플리케이션 배포 상황을 다음과 같이 유지해주세요”라는 desired state를 넘겨준다. 그러면 Kubernetes는 current state를 지속적으로 모니터링하고, current state와 desired state 사이에 다른 부분이 있을 경우 이를 일치하도록 만든다. 이 미묘한 차이를 이해하는 것이 Kubernetes를 쉽게 이해할 수 있는 핵심이다.
Kubernetes 공식 홈페이지에서도 위와 비슷한 이야기를 하고 있다.
Additionally, Kubernetes is not a mere orchestration system. In fact, it eliminates the need for orchestration. The technical definition of orchestration is execution of a defined workflow: first do A, then B, then C. In contrast, Kubernetes is comprised of a set of independent, composable control processes that continuously drive the current state towards the provided desired state. It shouldn’t matter how you get from A to C.
추가적으로, Kubernetes는 단순한 오케스트레이션 시스템이 아니다. 사실, Kubernetes는 오케스트레이션의 필요성을 없애버렸다. ‘오케스트레이션’의 정의는 workflow를 실행하는 것이다. 예를 들어, 우선 A를 실행하고, 그 다음 B를 실행하고, 마지막으로 C를 실행한다고 하는 workflow가 있으면 이를 그대로 실행해주는 것이다. 반면, Kubernetes는 현재 상태를 유저가 정의한 목표 상태로 끊임없이 맞춰가는 여러 개의 독립적인 컴포넌트로 구성되어 있다. 당신은 어떻게 A에서 C로 가는지 전혀 신경쓰지 않아도 된다.
Kubernetes Internals
이제 Kubernetes가 desired state를 유지하기 위해 내부적으로 어떻게 동작하는지를 알아보고, 이를 Kubernetes의 각 컴포넌트와 workload와 연결지어보자.
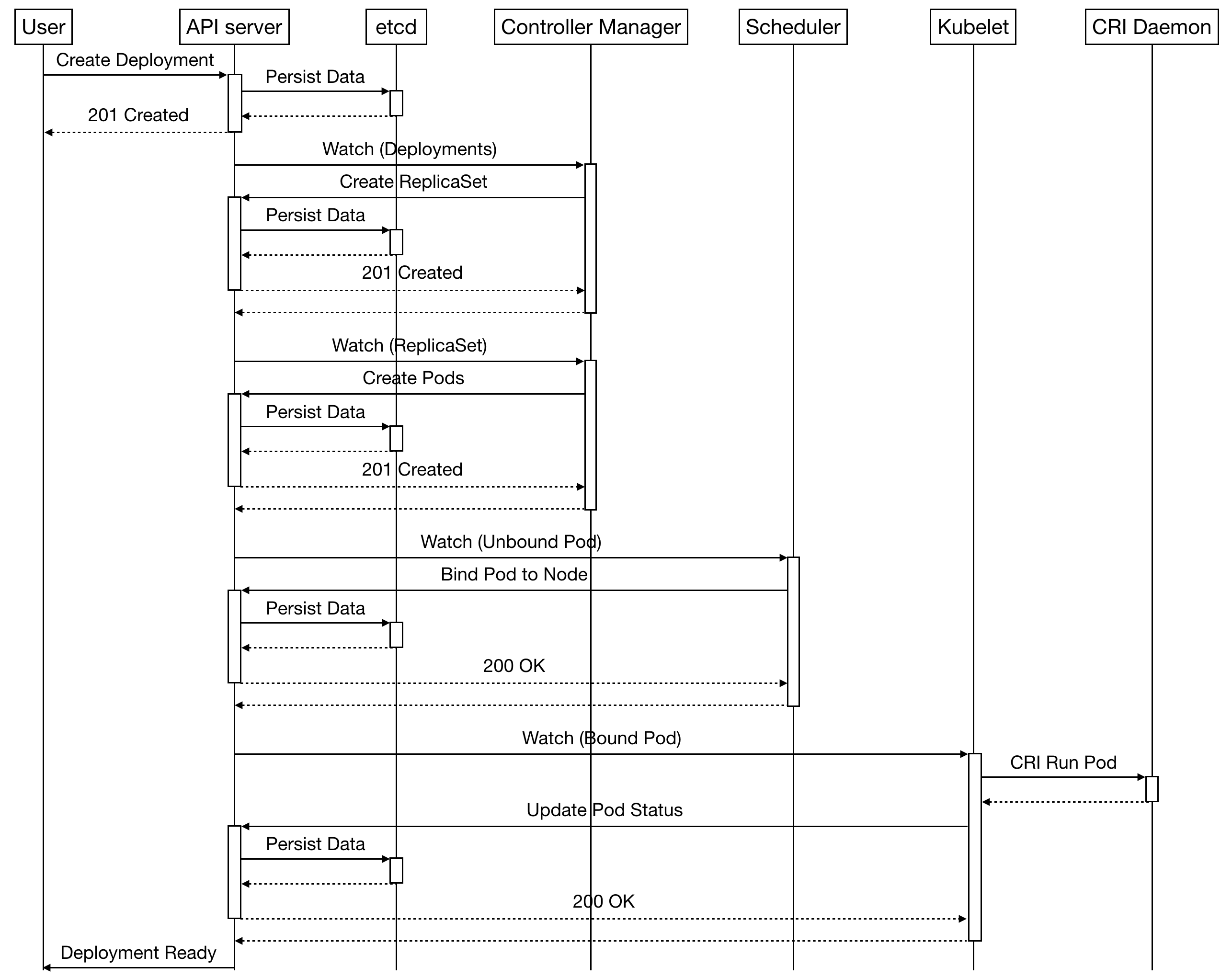
* 설명에 앞서, Kubernetes는 꽤나 많은 컴포넌트로 이루어져있다. 각 컴포넌트는 최소한의 책임을 가지고 각자 자기가 할 일만 수행하며, 컴포넌트들이 조합되었을 때 비로소 Kubernetes가 하나의 시스템으로 작동한다. 이 점을 유의하며 읽으면 도움이 될 것이다. 그리고 아래에 첨부된 Kubernetes flow diagram을 함께 보면서 읽으면 더욱 이해가 쉬울 것이다.
쉬운 설명을 위해, 우리가 Kubernetes를 통해서 한 어플리케이션을 배포하는 상황을 가정해보자. 이 어플리케이션을 구운 이미지는 이미지 A이다. 그리고 우리는 이 어플리케이션을 총 4대 띄우고 싶다.
우선, 위에서 Kubernetes는 desired state를 input으로 받는다고 했다. 일반적으로 유저가 정의하는 desired state는 Deployment object이다. 예를 들어, 유저는 kubectl을 통해 Kubernetes master node에 노출된 api server 컴포넌트에 “이미지 A의 컨테이너가 하나 있는 Pod을 4개 띄운 상태로 유지해주세요”라는 Deployment object를 만들라고 명령한다. 그러면 api server는 http 요청을 받고 etcd라는 저장소에 해당 Deployment object의 정보를 저장하기만 한다.
Deployment object를 저장하면, Controller Manager라는 컴포넌트가 이를 감지하고 이에 대응하는 ReplicaSet object를 생성한다. 위 상황에서는 “이미지 A에 대해 4개의 컨테이너 복사본을 유지한다”는 ReplicaSet object를 하나 만들라고 api server에게 명령할 것이다. 그러면 api server는 이를 etcd에 저장(생성)한다.
ReplicaSet object 역시 Controller의 일종이기 때문에, Controller Manager가 ReplicaSet object의 생성을 감지한다. 그러면 Controller Manager는 ReplicaSet object에 적힌 대로 이미지 A를 기반으로 Pod을 4개 생성한다. 여기서 중요한 것은 Controller Manager가 Pod을 실제 Node에 띄우지는 않고 단지 생성만 한다는 것이다.
이렇게 아무데도 띄워져 있지 않은 Pod을 어떤 Node에 띄울지 결정하는 것은 Scheduler의 책임이다. Scheduler는 실제 물리적인 서버에 띄워져 있지 않은 Pod을 감지하여 적절한 서버에 연결시켜주는 역할’만’ 한다. 심지어 띄워주지도 않고 어떤 Node에 띄워져야 하는지만 결정해서 etcd에 저장한다.
Scheduler가 Pod과 Node를 연결한 정보를 etcd에 적으면, 이 정보를 기반으로 실제 Pod을 Node에 띄우는 것은 각 Node에서 실행되고 있는 kubelet이라는 프로그램의 역할이다. kubelet은 자신의 Node에 Pod이 새로 할당되면 docker 같은 Container Runtime Interface(CRI)에 실제로 컨테이너를 띄우는 명령을 날린다.
이를 그림으로 정리하면 아래와 같다(강인호님 웨비나 자료의 사진 화질이 좋지 않아 그대로 따라 그려 사용).
위의 내용을 선언적으로(?) 표현해보면 다음과 같다.
- 모든 정보는 etcd에 저장되고 api server를 통해 각 컴포넌트에 노출된다.
- Kubernetes의 컴포넌트들은 전부 api server를 바라보며 변화를 감지하고 있다.
- 그러다가 자신의 책임인 변화가 감지되면 자신이 해야 할 일만 처리한다.
그리고 각 컴포넌트의 책임은 다음과 같다.
- api server: 유저나 다른 컴포넌트의 명령을 받아 object를 관리(CRUD)
- Controller Manager: 새로운 Controller를 감지하고 이를 처리
- Deployment Controller → ReplicaSet Controller
- ReplicaSet Controller → new unbound Pods
- Scheduler: unbound Pods를 감지하고 이를 처리
- unbound Pods → bound Pods
- kubelet: bound Pods를 감지하고 실제로 Pod을 띄움
이러한 상태 감지와 이에 대응되는 action은 끊임없이 이루어진다. Kubernetes는 지속적으로 각종 current state를 측정하여 저장한다. 그리고 각 컴포넌트는 자신이 바라보는 current state와 desired state가 일치하도록 최선을 다한다.
Kubernetes object 예시
Kubernetes를 단순히 action을 실행하는 tool로 보았을 때 이해가 잘 안 된 대표적인 요소가 바로 label과 label selector였다.
1 | apiVersion: apps/v1 |
위 예시는 간단하게 nginx 컨테이너 하나로 구성된 Pod의 복사본을 3개 띄우는 Deployment를 정의한 YAML 파일이다. 이 Deployment Controller를 생성하면 Kubernetes는 위에서 본 대로 ReplicaSet Controller를 만들고, Pod을 만들고, 해당 Pod를 Node에 bind 시키고, bind 된 Node는 Pod을 띄우는 일련의 과정을 수행할 것이다.
만약 단순히 Kubernetes가 특정 action을 input으로 받아 이를 수행하는 툴이었다면 YAML 파일은 단순히 아래와 같이 구성되어도 괜찮았을 것이다.
1 | apiVersion: apps/v1 |
이 정도의 정보로도 충분히 “nginx 컨테이너 하나로 구성된 Pod의 복사본을 3개 띄워주세요”라는 메세지를 전달할 수 있다.
하지만 우리가 Kubernetes에 전달하는 명령의 본질은 이것이 아니다. “nginx 컨테이너 하나로 구성된 Pod의 복사본을 3개 띄운 상태로 유지해주세요“이다. 이 명령을 수행하기 위해서 Kubernetes는 훨씬 더 많은 일을 해야 한다. 가장 중요한 일은 current state를 측정하는 것, 즉 이 명령을 위해 띄운 container가 몇 개인지 추적하는 일이다. 그래야 desired state를 이루기 위해 어떤 행동을 취할지 판단할 수 있기 때문이다. 이를 위해서는 어떤 Pod이 이 명령에 속하는 Pod인지 알 수 있어야 한다. 바로 이 때문에 Pod에 라벨을 붙이는 spec.template.metadata.labels.app field와, current state를 측정하기 위해 어떤 container를 counting해야 하는지를 정하는 spec.selector.matchLabels field가 필요하다.